
Mining Time Usage Models: A Practical Guide & Best Practices

Overview
In modern mining operations, effective mobile asset management relies on a granular understanding of how equipment time is utilised. The Time Usage Model (TUM) provides a standardised hierarchical framework to categorise equipment activity, facilitating the calculation of critical Key Performance Indicators (KPIs) like availability, utilisation, and operating efficiencies. Many mines struggle to adopt a standardised TUM with constant debate and lack of consensus; having a common TUM across multiple operations can sometimes require enormous will to implement.
Contents
The Core Time Usage Hierarchy
Evolving the TUM: Integrating Operational Technology (OT)
Important Note on KPIs driving the Wrong Behaviour
Avoid Mining Equipment KPIs that will be Inherently Unreliable
Individual Delay and Down Codes
Summary and Recommendations
FAQ on Mining Time Usage Models

Establishing a standardised site or company wide Time Usage Model is essential
The Core Time Usage Hierarchy
The foundation of the TUM is the systematic breakdown of Calendar Time (CT) into specific blocks that define equipment readiness and state.
1. Total Time and Calendar Time
Calendar Time (CT): The total period under consideration (e.g., 24 hours). It is the sum of Available Time (AT) and Down Time (DT).
Decommissioned Time (DC): This is not always implemented but we believe it is important for KPIs that truly reflect an operation’s equipment performance. Time where an asset is removed from the active fleet for long-term storage or disposal.
Total Time (TT) is calculated as CT + DC.
2. Available Time (AT)
Available Time represents the period when the equipment is mechanically, electrically capable of performing its intended function or put simply; it's not broken down or on planned maintenance. It is typically further categorised into:
Utilised Time (UT): The period when the equipment is active and contributing to mining operations.
Operating Standby (OS): Time when equipment is available but not active due to lack of operator or operational requirement.
No Scheduled Production (NSP): Time when the asset is available but there is no plan to operate it (e.g., mine closure, plant shutdown, holidays). Note that some mines are tempted to use this category to make certain KPIs look better. This should only be used when no scheduled production is truly planned rather than a last minute pivot on shift
If you have a suitable detail of reliable data, we suggest you also add Productive Time and Non Productive Time. Examples of this are loading (productive) and hanging (non-productive). Avoid doing this if your data isn’t accurate enough.
3. Down Time (DT)
Downtime occurs when equipment is unavailable to work due to planned maintenance or an unplanned stoppage (otherwise known as a breakdown). Key categories typically include:
Scheduled Downtime (SD): Planned maintenance activities (e.g., PM, pre-PM inspections, component change out).
Unscheduled Downtime - Asset (UDA): Unplanned mechanical or electrical failures of the machine itself.
A further category which we encourage mines to embrace is to cover downtime not related to core equipment maintenance
Unscheduled Downtime - Other (UDO): Stoppages caused by factors external to the machine's core function, such as technology failures or logistical constraints.
Evolving the TUM: Integrating Operational Technology (OT)
The rise of Autonomous Haulage Systems (AHS), Fleet Management Systems (FMS), and Collision Avoidance has introduced new failure modes. Traditional TUM models often hide technology failures within general downtime, which can misrepresent the performance of both maintenance and operational technology departments.
Best Practice for OT Classification: MTS recommends isolating Technology Downtime to provide clarity on system reliability without penalizing mechanical availability metrics.
Functional Failure approach: If a technology system (e.g., CAS or Fatigue Monitoring) is required by site regulations for operation, its failure should be treated as a functional failure (Downtime).
"Other Down" approach: The failure would be classified under Unscheduled Down - Other.
Scheduled downtime for mining technology should go under “Scheduled Down” however some sites do have a separate “Scheduled Down - Other”. This can introduce complexities for those entering in downs but does bring an ease to downstream reporting.
Essential Asset Performance Metrics
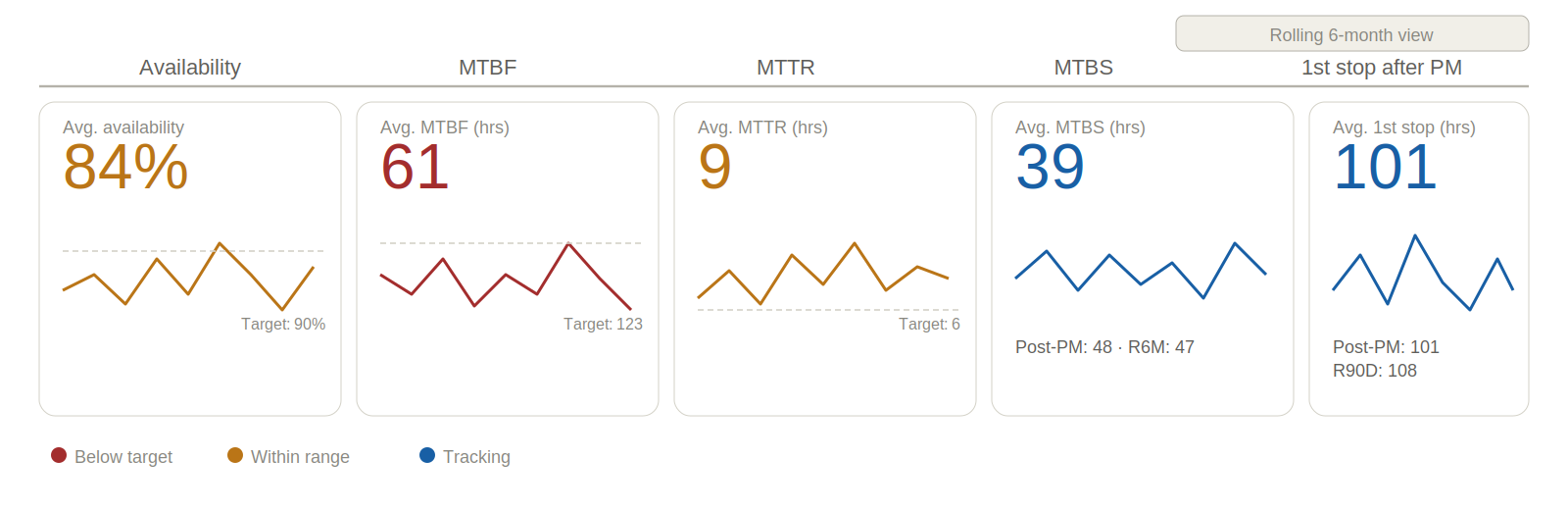
Some typical KPI’s for Mining Mobile Asset Reliability Performance
Using the categories defined above, the following table highlights some of the most common KPIs used in the industry:
| Metric | Technical Calculation | Business Purpose |
|---|---|---|
| Availability | AT / CT | Measures the percentage of time the asset is available to work. |
| Utilisation | UT / CT | Measures the total active time relative to the calendar period. |
| Use of Availability (UOA) | UT / AT | Highlights how much use the operation is getting out of the asset when it is available to work. |
| Effective Utilisation | OT / CT | This is a measure of the % of total time that the asset is operating. |
| Operating Efficiency (OE) | OT / UT | Measures productive work (OT) versus total active time (UT), highlighting delays. |
| MTBF | UT / Unscheduled Stoppages | Indicates how long a piece of equipment will typically run without a breakdown. |
| MTTR | DT / Total Stoppage Count | Measures on average how long it takes to carry out repairs. |
Important Note on KPIs driving the Wrong Behaviour
Care really needs to be taken when rolling out the use of KPIs within an organisation. Putting too much emphasis on a certain KPI could lead crews to conduct all manner of obviously wrong behaviours simply to hit a target. Below are two examples we’ve seen at mines in recent years:
Utilisation: Focusing too heavily on utilisation which results on a shift simply running every piece of available equipment to have a high number. (Rather than focusing on operating efficiency and indeed drilling down to look at the split of productive versus non-productive mining activities)
Tonnes per Hour: Crews short dumping in a shift to achieve a ridiculously high tonnes per hour.
Avoid Mining Equipment KPIs that will be Inherently Unreliable
If you have your VIMS/VHMS equipped trucks running a modern fleet management system, you are likely to be able to have highly accurate KPIs for operating efficiency, tonnes per hour per EFH etc. This is because a lot of your data capture will be automated and it will have a deep grain of detail (i.e. tonnes, speeds, activity times). However you won’t be able to replicate this for your ADT fleet where you are just receiving basic data (assuming it has no FMS on it). Therefore be reasonable and manage expectations in what can be measured and benchmarked for your various fleets.
Individual Delay and Down Codes
Care should be taken when selecting your set of delay and down codes. It is important that over complexity is avoided to prevent confusion, “duplicate” codes across multiple categories should be avoided. Here are some tips when creating your delay and down codes:
Agree across all departments the set of codes
When setting up in your FMS, ensure you spell check and configure for the right machine classes and exclude from the onboard where possible.
Avoid the tendency to add new delays and downs in a knee jerk reaction.
Take care when renaming delays or downs as it's possible you could break some of your site reporting.
If possible tie to SEMC codes
Ensure you have appropriate training material including cheat sheets for operators and dispatchers.
If taking a corporate model, exclude any that are obviously never going to be used at your operation (i.e. you don’t need a snow delay in the tropics).
Summary and Recommendations
Standardising your Time Usage Model is incredibly important for every mining operation; and ideally mining houses should standardise across their multiple operations.
Agree on a Standardised, Realistic TUM: Work across departments to define the TUM
Avoid Complexity by ensuring you only create a TUM and subsequently KPIs that can be reliably measured with your source data.
Automate Data Capture via FMS and onboard telemetry to ensure the accuracy of "Unknown Time" and operational delays.
Standardise Reporting across the operation(s) to ensure everyone is looking at the same metrics.
For sites looking to refine their performance reporting, MTS provides the expertise to align legacy systems with modern industry standards, ensuring your metrics truly reflect operational reality.
FAQs on Mining Time Usage Models
How should we implement a standardised TUM across multiple operations?
A standardised Time Usage Model (TUM) should be developed through a workshop involving key stakeholders from each site (including maintenance, operations, and planning) and led by a head office sponsor. This workshop should aim to review current site models, integrate the best practices from each, and achieve consensus on:
The standardised TUM structure.
Upstream delay/down codes.
Downstream Key Performance Indicators (KPIs) and reporting methods.
How to avoid breaking our reporting?
Firstly ensure that when you implement a TUM (or a new FMS) that the vendor team supporting you properly implements it in the reporting database. Evidence of its validation should be provided. If you are always putting in workarounds at reporting level then it's usually an indicator that it wasn’t set up properly.
What downs and delays should be exposed to the operators?
Some FMS such as Cat MineStar Fleet enable administrators to specify if a delay or down code can be available onboard or just in the office. This feature should really be taken advantage of with any maintenance delays being removed and the operators left with a simple placeholder delay of “Breakdown” and “Planned Maintenance”. Once the equipment is stopped, dispatchers can then change to a more specific tune such as “Engine”.
How to best ensure Data Quality and Integrity for TUM Data, Site Performance KPIs?
We would recommend introducing both TUM and down/delay code validation dashboards for each mine. These should be on a shift grain and dispatchers should have the responsibility for monitoring during the shift for any issues. The system administrator should then have overall responsibility for ensuring from shift to shift the data is clean. Finally the maintenance department should review all maintenance related stoppages on a daily basis so as to avoid a reporting crisis at the end of the week.
What happens if our TUM, delays and downs have become overly complex?
Stop digging. Schedule a workshop where consensus can be gained on what can be stripped out. An evaluation of impacted reports and systems integrations will then need to take place. A work plan should then be developed to implement the system changes, conduct suitable change management and update impacted reports/dashboards. Do not underestimate the potential complexity of this project but it is well worth considering.
How do we expand performance monitoring to auxiliary equipment?
Often focus is on the heavy mining fleet, however with many smaller pieces of equipment (support excavators, rock breakers, compactors) now coming with onboard systems such as VisionLink as standard, it is possible to pull this data down so that you start to get basic operating times, standby times etc. It is also relatively straightforward to further improve reporting detail by tying the equipment into the fleet management system as well (without fitting an expensive display). We have had great success doing this and recommend that you consider the same for your mine.